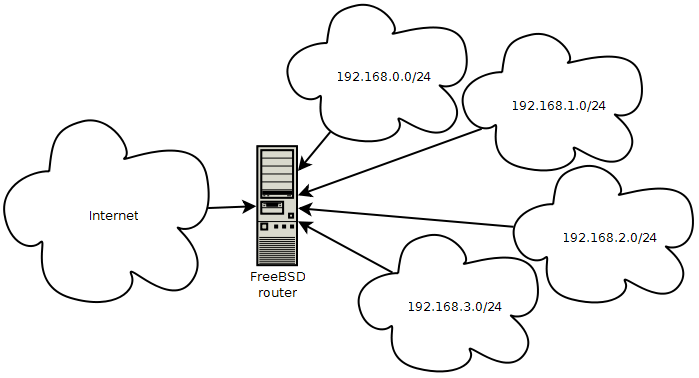
Количество компьютеров на предприятии постепенно увеличивалось, необходимо было или менять маску подсети, или добавлять дополнительно, еще 3 подсети.
Было принято второе решение, и так поехали. Процесс первоначальной установки FreeBSD описывать не буду (жуем хэндбук).
Схема маршрутизации сети:
shema2
Первым делом добавим необходимые параметры в /etc/rc.conf:
#шлюз по умолчанию, на этот адрес идет все то, что не принадлежит нашей сети. defaultrouter=«193.15.58.78»#у меня vr0 — сетевушка которая смотрит в мою сеть, все остальное алиасы на разные подсети ifconfig_vr0=«inet 192.168.0.1 netmask 255.255.255.0» ifconfig_vr0_alias0=«inet 192.168.1.1 netmask 255.255.255.0» ifconfig_vr0_alias1=«inet 192.168.2.1 netmask 255.255.255.0» ifconfig_vr0_alias2=«inet 192.168.3.1 netmask 255.255.255.0»#прописываем статические маршруты static_routes=«net1 net2 net3 net4» route_net1=«-net 192.168.0.0/24 192.168.0.1» route_net2=«-net 192.168.1.0/24 192.168.1.1» route_net3=«-net 192.168.2.0/24 192.168.2.1» route_net4=«-net 192.168.3.0/24 192.168.3.1»
#разрешаем маршрутизацию на интерфейсах gateway_enable=«YES»
Перезагружаемся или выполняем /etc/netstart для перечитывания rc.conf и применения настроек. Теперь все четыре подсети будут доступны между собой.
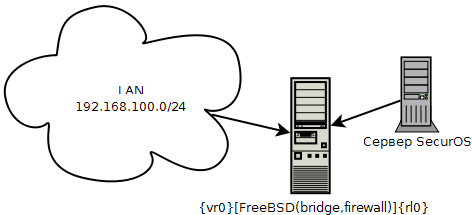
Необходимо было защитить сервер доступа к турникетам на платформе SecurOS. Было принято решение настроить брандмауэр на основе сетевого моста.
Схема сети:
Для работы моста требуются не менее два сетевых адаптера. У меня это vr0 и rl0.
Для включения поддержки сетевого моста, необходимо добавить строчку в ядре:
# cd /usr/src/sys/i386/conf
# cp GENERIC PFBRIDGE
# ee PFBRIDGE
#Включение в ядро функции сетевого моста
device if_bridge
Так, как я использую межсетевой экран PF, я добавлю его поддержку в ядро:
# cd /usr/src
# make buildkernel KERNCONF=PFBRIDGE
# make installkernel KERNCONF=PFBRIDGE
#reboot
Добавим параметры в /etc/sysctl.conf:
#Для фильтрации пакетов на входящих и исходящих интерфейсах
net.link.bridge.pfil_member=1#Для фильтрации пакетов на интерфейсе bridge0
net.link.bridge.pfil_bridge=0
далее в /etc/rc.conf пишем:
#назначаем IP сетевым интерфейсам
ifconfig_vr0="inet 192.168.100.20 netmask 255.255.255.0"
ifconfig_rl0="inet 192.168.100.30 netmask 255.255.255.0"#создаем новый интерфейс bridge0
cloned_interfaces="bridge0"#добавляем сетевые для роботы в качестве моста
ifconfig_bridge0="addm vr0 addm rl0 up"
Перезагружаем сервер и проверяем работоспособность моста.
Вот что должно появиться у вас после перезагрузки:
Итак, имеется локальная сеть и канал провайдера. Задача — обеспечить определенным пользователям сети доступ к каналу провайдера. При этом ширина канала ограничена, поэтому его необходимо распределить между пользователями «справедливо», то бишь поровну, но при этом по возможности максимально использовать его ширину.
Решение поставить для каждого пользователя ограничение ширина_канала/количество_пользователей по очевидным причинам неприемлемо — при такой политике полная ширина канала будет задействована очень редко, так как глупо ожидать, что все пользователи будут пользоваться им одновременно и полностью исчерпывать свою «долю».
Варианты вроде собрать статистику и поставить ограничение, исходя из среднего количества активных пользователей тоже восторга не вызывают, по тем же причинам.
Вывод — фиксированное ограничение скорости тут не пройдет, надо копать глубже.
Выбор платформы
Из средств контроля траффика мне сразу попались на глаза штатный [urlspan]FreeBSD[/urlspan]-шный шейпер [urlspan]dummynet[/urlspan] и механизм альтернативного построения очередей altq, поддерживаемый штатным [urlspan]OpenBSD-шным фаерволлом pf[/urlspan].
Опыта работы ни с первым, ни со вторым у меня не было, поэтому мой выбор в некоторой мере субъективен. Я остановился на pf+altq, потому что мне в любом случае нужно было обеспечить [urlspan]NAT[/urlspan], а pf в этом более удобен, чем, скажем, [urlspan]ipfw[/urlspan].
Кроме того, высказывалось мнение что altq использует более «умные» и гибкие мехенизмы, нежели dummynet. Да и идея об иерархической структуре очередей с возможностью для потомка позаимствовать (borrow) траффик у родительской очереди в контексте поставленной задачи выглядит симпатично.
И, наконец, как оказалось, под pf существует авторизационный шелл [urlspan]authpf[/urlspan], но об этом позже.
Итак, дальше работаем с FreeBSD 6.2 + pf.
Теория
Теперь несколько слов о том, как осуществляется контроль входящего трафика (а для большинства пользователей именно входящий трафик является основным). Самый лаконичный и строгий ответ, как ни странно, — никак!
Действительно, мы вольны как угодно шейпить (читай: дропать) пришедшие пакеты. Но они ведь уже пришли! А следовательно — заняли часть используемого канала.
Как же быть? Тут на помощь приходит реализованные в протоколе TCP средства контроля скорости. Грубо говоря, если от получателя не пришли подтверждения о получении определенного количества пакетов — передатчик начинает отсылать их медленнее, подстраивая скорость под технические возможности линии связи. Так, через некоторое время (не мгновенно!) канал будет занят настолько, насколько мы обрезали входящий трафик.
Разумеется, такой механизм не сработает, если канал был намеренно перегружен недоброжелателем — он не станет отсылать пакеты медленнее, увидев, что не все они успевают обрабатываться. Но это уже другая история.
Подробнее об этом можно почитать здесь.
Итак, делить между пользователями мы будем только исходящий (для шлюза) трафик. И если все, что исходит через внешний сетевой интерфейс находится под полным контролем (сколько надо — столько и отправим провайдеру), то для трафика, приходящего от провайдера, остается лишь надеяться на то, что его источник подстроится под ограничения, которые мы установим для исходящего трафика на внутреннем сетевом интерфейсе.
Особенности pf
Заранее отмечу пару фактов о файерволе pf, которые обязательно надо иметь в виду.
Механизм altq работает только для исходящего трафика. Это действительно так, но эта особенность нам мешать не будет, поскольку мы сделаем так, как было упомянуто выше: применим altq к исходящему трафику на внутреннем интерфейсе (а не к входящему на внешнем).
В секцию фильтров пакеты попадают после обработки NAT-ом. Это тоже действительно так. Чем это может нам помешать? А тем, что по нужным очередям пакеты рассовываются именно в секции фильтров, а рассовывая их, нам надо знать, от какого пользователя (читай: с какого адреса) они пришли на шлюз. Но эта особенность нам мешать тоже не будет, поскольку фильтры мы определим для внутреннего интерфейса (через который пакеты приходят еще не обработанные NAT-ом). При этом интересно обратить внимание на то, что фильтр будет применяться к пакету на одном интерфейсе, и засовывать его в очередь другого интерфейса. (Такой подход в самом деле не очевиден — в рассылках встречались вопросы по pf вроде «зачем позволять присваивать очередям входящий трафик, если очереди работают только для исходящего» или «зачем позволять присваивать пакеты, проходящие через один интерфейс, в очередь на другом».)
При использовании keep-state пользовательскими фильтрами обрабатывается только первый (state-creating) пакет. Это мешает нам тем, что если пользователь отправляет один запрос, то он, как исходящий, становится в соответствующую очередь. Но когда пользователю приходит ответ, то при использовании keep-state таблица правил не просматривается, — вместо этого к новому пакету применяются те же правила, что и к первому. То есть он становится в очередь для исходящего траффика на внешнем интерфейсе — а это совсем не то, что нам требуется. Однако, эта особенность, опять же, мешать не будет — мы откажемся от keep-state.
Трудно поверить, но стройность этих теоретических рассуждений не подвела и на практике.
Начинаем: авторизация
Здесь не будет рассматриваться настройка маршрутизации, так как она рассмотрена во множестве других материалов. Итак, шлюз заработал как роутер, теперь займемся авторизацией.
Первое, что выдал Google по этому поводу — это authpf, авторизационный шелл для шлюза, использующего pf.
Работает он следующим образом. Он назначается в качестве login shell для пользователей, которые должны авторизоваться, и следовательно, запускается каждый раз, когда пользователь открывает ssh-сессию. Запускаясь, он динамически изменяет правила файерволла pf, используя механизм anchor-ов и таблиц. Эти правила остаются в силе до тех пор, пока соответствующая ssh-сессия не прервется. Дешево и сердито.
Средства, предоставляемые authpf, довольно гибки, — скажем, можно определить динамические правила, индивидуальные для каждого пользователя. Однако... для намеченной цели (задание разделения траффика между пользователями в зависимости от количества пользователей, авторизовавшихся в данный момент) требуется каждый раз, когда пользователь зашел/вышел менять определения очередей в правилах pf, вплоть до добавления новых очередей и удаления старых. К сожалению, механизм anchor-ов делать этого не позволяет, поэтому придется перезагружать полный список правил.
Динамическое построение очередей: генерируем правила
Оговорюсь (возможно, запоздало), что не буду дублировать официальную документацию. За ней обращайтесь к первоисточникам, а точнее — к man-ам по [urlspan]pf.conf (5)[/urlspan] и [urlspan]authpf (8)[/urlspan].
Определимся, что должно происходить при изменении количества залогиненых пользователей.
Во-первых, должен изменяться раздел таблиц правил pf. Он должна выглядеть примерно так:
Почему именно таблицы, а не простые макроопределения? Дело в том, что authpf позволяет одновременную авторизацию с нескольких IP-адресов, и хочется, чтобы эта его возможность поддерживалась, причем канал при этом должен делиться не между IP-шниками, а между пользователями.
Во-вторых, измениться должен раздел очередей. Для ясности отмечу, что в pf.conf прописаны следующие определения (они меняться не будут):
Здесь активирован механизм altq на внешнем и внутреннем интерфейсах, и на каждом из них определены очереди для связи с провайдером, и default — необходимая очередь, в которую попадают пакеты, не попавшие ни в какую другую. (Определения, не имеющие отношения к решаемой задаче, здесь и ниже будут опускаться, чтобы не захламлять текст).
Динамическая часть раздела очередей должна выглядеть примерно так (продолжая предыдущий пример):
queue inet_in on $int_if bandwidth 1280Kb { user1_in, user2_in }
queue inet_out on $ext_if bandwidth 320Kb { user1_out, user2_out }
queue user1_in bandwdth 50% cbq(red, borrow)
queue user1_out bandwidth 50% cbq(red, borrow)
queue user2_in bandwidth 50% cbq(red, borrow)
queue user2_out bandwidth 50% cbq(red, borrow)
# ... и так далее, по две очереди на каждого пользователя, для входящего и
# исходящего трафика
Причем эти 50% для троих залогиненых пользователей превратятся в 33%, для четверых — в 25%, и так далее.
И, наконец, должен обновиться раздел фильтров, чтобы правильно рассовать пакеты по очередям:
pass out in $int_if from !<lan to <user1_ips queue user1_in
pass out in $int_if from <user1_ips to !<lan queue user1_out
pass out in $int_if from !<lan to <user2_ips queue user2_in
pass out in $int_if from <user2_ips to !<lan queue user2_out
# ... и т. д.
Как можно было догадаться, все идет к написанию шелл-скрипта, который будет брать за основу существующий pf.conf и вставлять в нужные места динамически генерируемые части. Чтобы облегчить ему (скрипту) работу, в pf.conf были добавлены специальные комментарии-флажки: #%T, #%Q, #%F — в тех местах, куда следует вставлять указанные три сгенерированых куска.
Такой скрипт (/etc/authpf/requeue) и был написан. Он, основываясь на выводе команды ps, (благо, разработчики authpf позаботились о том, чтобы вывод ps был легко обрабатываемым, об этом — дальше), с помощью grep-ов и sed-ов создает нужные списки, читает pf.conf и создает «новый» список правил — со вставленными новыми кусками, после чего загружает его с помощью pfctl.
Отслеживание входа-выхода: ковыряем authpf
Теперь, когда скрипт готов, надо определиться, когда и как его запускать. Cron тут не поможет — если пользоваться только им, то пользователь, авторизовавшись вынужден будет ждать в среднем полминуты перед тем, как под него создастся очередь. Естественнее всего запускать скрипт при каждой успешной авторизации в authpf и при каджом завершении сессии authpf. Увы, в документации по authpf не было найдено ничего по запуску пользовательских программ при этих событиях. Значит, придется добавить нужную функциональность самостоятельно.
Нужные места в исходнике authpf (/usr/src/contrib/pf/authpf/authpf.c) нашлись без труда, и код в них дополнен.
Определение глобальной переменной для формирования строки, передающейся командному интерпретатору:
char *prompt;
Запуск скрипта при успешной авторизации:
printf(, luser);
printf("You are authenticated from host ""rn", ipsrc);
setproctitle(, luser, ipsrc);
/* мой код */
asprintf(&prompt, , PATH_RUN, luser, ipsrc, (long)getpid());
system(prompt);
free(prompt);
/* конец */
print_message(PATH_MESSAGE);
Запуск скрипта при закрытии сессии:
if (active) {
change_filter(0, luser, ipsrc);
change_table(0, luser, ipsrc);
authpf_kill_states();
remove_stale_rulesets();
/* мой код */
setproctitle("dying");
asprintf(&prompt, , PATH_STOP, luser, ipsrc, (long)getpid());
system(prompt);
free(prompt);
/* конец */
}
И в файле pathnames.h определения путей к скриптам:
После этого authpf был пересобран и переустановлен:
# cd /usr/scr/usr.sbin/authpf
# make
# make install
Что это дало? Теперь после успешной авторизации будет запускаться /etc/authpf/authpf.run с тремя параметрами: имя авторизовавшегося пользователя, IP-адрес, с которого прошла авторизация, и pid шелла, из которого был запущен скрипт. После закрытия сессии будет вызываться /etc/authpf/authpf.stop с теми же параметрами.
Обратите внимание на вызовы setproctitle () — они изменяют название процесса, которое выводится командой ps.
Первый вызов присутствовал изначально — специально дла того, чтобы можно было в любой момент просмотреть список авторизовавшихся пользователей простым «ps | grep authpf». Принципиально, чтобы наш скрипт выполнялся после вызова setproctitle () — так как он использует именно вывод ps.
Второй вызов был добавлен мной. Зачем? Дело в том, что во время выполнения «завершающего» скрипта процесс authpf, который готовится «умереть», все еще висит в выводе ps. Но в то же время он там не нужен — мы ведь хотим, чтобы очередь выходящего пользователя удалилась. Это достигается изменением заголовка процесса authpf на “dieing” — он все равно будет в выводе ps, но отбросится grep-ом внутри скрипта.
Вообще говоря, только что была сделана сомнительная вещь — добавление не очень культурного кода в часть проекта OpenBSD, один из принципов которого — постоянный аудит кода и исправление мельчайших, даже незначительных ошибок.
Что же некультурного в добавленном? Во-первых, вызов asprintf () может завершиться неудачей из-за нехватки памяти, и эту ситуацию следует обрабатывать. Во-вторых, вызов system () может повлечь появление на стандартном выводе ненужной информации (например, сообщения об ошибке), которая станет видна авторизовавшемуся пользователю, а это ему ни к чему. Чтобы избежать этого, придется внимательно следить, чтобы скрипты были на месте, права доступа позволяли их запускать, и чтобы они (скрипты) не производили нежелательного вывода.
Откровенно говоря, эти «некультурности» были оставлены в таком виде в значительной степени из-за моей лени. Что ж, на моей совести осталось пятно — но давайте двигаться дальше.
Права доступа: setuid-ные страсти
Возвращаясь к скрипту /etc/authpf/requeue вспомним, что он изменяет конфигурацию pf, а следовательно — должен выполняться с правами root. Setuid для шелл-скриптов не работает, поэтому напишем короткую программу на C:
int main (int argc, char argv[])
{
system(/etc/authpf/requeue);
return 0;
}
Скомпилируем ее в /etc/authpf/requeue.suid, и установим для нее владельца и права доступа:
Теперь кто бы ни запустил requeue.suid — она будет выполняться с правами root. В то же время правами на ее запуск обладает только группа authpf. А права группы authpf можно получить только из setgid-ного authpf, который стоит в качестве login shell у наших пользователей.
Таким образом обеспечивается возможность запуска потенциально опасной программы только в тех случаях, когда это действительно требуется.
Последние штрихи: связываем все воедино
Теперь осталось разместить скрипты, выполняющиеся при входе и выходе пользователя из системы там, где их ожидает найти authpf.
Небольшое отступление. В процессе отладки работы своего творения я несколько раз сталкивался со «сверхестественными» непонятностями. Вся эта «сверхестественность», как оказывалось потом, была результатом банальной невнимательности.
Однако одно из «чудес» пока остается для меня чудом. А именно — если запускать requeue из authpf.stop без “&" в конце — скрипт виснет на операциях rm и mv. C “&" — работает весьма быстро и вполне корректно. Буду благодарен, если кто-нибудь просветит меня, почему так происходит.
Заключение
Итак, несмотря на внешнюю аляповатость, все «это» в конце-концов заработало.
Полагаю, излишне предупреждать о том, что получившийся инструмент особо жесткому тестированию не подвергался, возможно, содержит ошибки, и не претендует на безукоризненность.
Приложения
/etc/authpf/requeue
Тот самй скрипт, который запускается каждый раз, когда очередной пользователь заходит/выходит. Помимо того, о чем говорилось в статье, в нем реализовано отделение UA-IX от не-UA-IX траффика (дублируя политику провайдера).
#!/bin/sh
log() echo "`date +%Y-%m-%d %H:%M:%S` [$$] ${log_msg}"
log_msg="(II) Requeuing started"
log
# prefix for temporary files
prefix=/tmp/authpf.requeue.
# lock file, exists while script is running
lock=${prefix}lock
# file to store active authpf login entries
users_table=${prefix}users_table
# file to store active authpf users
users_list=${prefix}users_list
# files to store dynamical parts of pf.conf
tables=${prefix}tables
queues=${prefix}queues
filters=${prefix}filters
rules=${prefix}rules
# initial pf.conf
pf_conf=/etc/pf.conf
# previously loaded rules
old_rules=${rules}.old
# file to store invalid rules for debug
bad_rules=/var/log/authpf.requeue.bad_rules
# total inbound and outbound bandwidths, Kbit/s
inet_in=1280
inet_out=320
uaix_in=3072
uaix_out=$uaix_in
# delay before retry if another instance of the script is running
retry_timeout=3
# check if another instance of the script is running
if [ -f ${lock} ]; then
pid=`cat ${lock}`
ps p${pid} /dev/null
if [ 0 -eq $? ]; then
log_msg="(II) Another instance is running, sleeping"
log
while ps p${pid} /dev/null; do
# sleep for retry
sleep ${retry_timeout}
done
log_msg="(II) Waked up"
log
else
log_msg="(WW) Previous instance terminated uncleanly"
log
fi
# block other instances of the script until we finish
echo $! ${lock}
# regular expression corresponding to autph entry is ps output
authpf_regex='^.* (.*)@(.*) (authpf)$'
# save table of users currently logged in via authpf (like 'username host')
ps ax | grep "${authpf_regex}"| sed "s/${authpf_regex}/1 2/" ${users_table}
# check if any user logged in
cat ${users_table} | grep "^.*$" /dev/null
if [ 0 -eq $? ]; then
# at least one user is logged in
# get complete list of logged in users
cat ${users_table} | sed "s/^(.*) (.*)$/1/" | sort | uniq ${users_list}
# get comma-separated lists like 'foo_in, bar_in' and 'foo_out, bar_out'
users_inet_in=`cat ${users_list} | sed "s/^(.*)$/1_ii,/"`
users_inet_in=`echo ${users_inet_in} | sed "s/^(.*),$/1/"`
users_uaix_in=`cat ${users_list} | sed "s/^(.*)$/1_ui,/"`
users_uaix_in=`echo ${users_uaix_in} | sed "s/^(.*),$/1/"`
users_inet_out=`cat ${users_list} | sed "s/^(.*)$/1_io,/"`
users_inet_out=`echo ${users_inet_out} | sed "s/^(.*),$/1/"`
users_uaix_out=`cat ${users_list} | sed "s/^(.*)$/1_uo,/"`
users_uaix_out=`echo ${users_uaix_out} | sed "s/^(.*),$/1/"`
# reset temporary files
truncate -s0 ${tables}
truncate -s0 ${queues}
truncate -s0 ${filters}
truncate -s0 ${rules}
# define parent queues
echo "queue inet_in on $int_if bandwidth ${inet_in}Kb { ${users_inet_in} }" ${queues}
echo "queue uaix_in on $int_if bandwidth ${uaix_in}Kb { ${users_uaix_in} }" ${queues}
echo "queue inet_out on $ext_if bandwidth ${inet_out}Kb { ${users_inet_out} }" ${queues}
echo "queue uaix_out on $ext_if bandwidth ${uaix_out}Kb { ${users_uaix_out} }" ${queues}
# evaluate per-user bandwidth quota, %
users_num=`cat ${users_list} | grep -c "^.*$"`
bw_quota=`expr 100 / ${users_num}`
# continue with per-user definitions
users=`cat ${users_list}`
for user in ${users}; do
# define table containing hosts from where user is logged in
user_regex="^${user} (.*)$"
ips=`cat ${users_table} | grep "${user_regex}" | sed "s/${user_regex}/1,/"`
ips=`echo ${ips} | sed "s/^(.*),$/1/"`
echo "table <${user}_ips { ${ips} }" ${tables}
# define user's personal queues
echo "queue ${user}_ii bandwidth ${bw_quota}% cbq(red, borrow)" ${queues}
echo "queue ${user}_ui bandwidth ${bw_quota}% cbq(red, borrow)" ${queues}
echo "queue ${user}_io bandwidth ${bw_quota}% cbq(red, borrow)" ${queues}
echo "queue ${user}_uo bandwidth ${bw_quota}% cbq(red, borrow)" ${queues}
# define filter rules for queue assignment
echo "pass out on $int_if from !<lan to <${user}_ips queue ${user}_ii" ${filters}
echo "pass out on $int_if from <uaix to <${user}_ips queue ${user}_ui" ${filters}
echo "pass in on $int_if from <${user}_ips to !<lan queue ${user}_io" ${filters}
echo "pass in on $int_if from <${user}_ips to <uaix queue ${user}_uo" ${filters}
done
# insert auto-generated parts into initial pf.conf
exec < ${pf_conf}
while read line; do
case "${line}" in
"#%T") cat ${tables} ${rules};;
"#%Q") cat ${queues} ${rules};;
"#%F") cat ${filters} ${rules};;
*) echo ${line} ${rules};;
esac
done
# remove unnesesary temporary files
rm ${tables}
rm ${queues}
rm ${filters}
rm ${users_table}
rm ${users_list}
else
# nobody logged in
# just use unchanged initial pf.conf
cp ${pf_conf} ${rules}
diff ${rules} ${old_rules} /dev/null
if [ 0 -ne $? ]; then
# Now ${rules} are ready for loading! Take a deep breath...
pfctl -f ${rules} /dev/null 2/dev/null
pfctl_ret=$?
if [ 0 -ne ${pfctl_ret} ]; then
log_msg="(!!) Failed to load generated rules (${pfctl_ret})"
log
echo =========================================== ${bad_rules}
date ${bad_rules}
echo =========================================== ${bad_rules}
cat ${rules} ${bad_rules}
else
log_msg="(II) Rules loaded succesfully"
log
cp ${rules} ${old_rules}
else
log_msg="(II) Rules have not been changed, loading skipped"
log
# we have finished, release the lock
rm ${lock}
related files
Список файлов, созданных в процессе реализации системы.
права доступа
владелец
путь
описание
rwxr--r--
root:wheel
/etc/authpf/requeue
Тот самый скрипт
rws--x---
root:authpf
/etc/authpf/requeue.suid
C-программа, запускающая requeue с правами root
rwxr-x---
root:authpf
/etc/authpf/authpf.run
Скрипт, запускаемый authpf при входе пользователя
rwxr-x---
root:authpf
/etc/authpf/authpf.stop
Скрипт, запускаемый authpf при выходе пользователя
rw-rw----
root:authpf
/var/log/authpf.inout
Лог, фиксирующий вход/выход пользователей
rw-rw----
root:authpf
/var/log/authpf.requeue
Лог, фиксирующий подгрузку сгенерированных правил в pf
rw-rw----
root:authpf
/var/log/authpf.requeue.bad_rules
Сюда для дебага сохраняются сгенерированные правила, которые pf отказался «кушать»
When rebooting after a panic, send an encrypted email containing basic
dump metadata along with a kernel backtrace, in order to assist FreeBSD
developers in identifying and fixing common panics.
If you install this and add
panicmail_enable="YES"
to your /etc/rc.conf, a panic report will be generated and sent to root@ for
you to review and submit (via email). You can skip the reviewing step and
submit panics automatically by setting
panicmail_autosubmit="YES".
The panics submitted are encrypted to an RSA key which I hold in order to keep
them secure in transit; and I intend to keep the raw panic reports confidential
except to the minimum extent necessary for other developers to help me process
the incoming reports.
If I receive enough panic reports to be useful, I hope to provide developers
with aggregate statistics. This may include:
* regular email reports listing the «top panics», to help guide developers
towards the most fertile areas for stability improvements;
* email to specific developers alerting them to recurring panics in code they
maintain (especially if it becomes clear that the panic has been recently
introduced); and
* guidance to re@ and secteam@ about how often a particular panic occurs if
an errata notice is being considered
as well as other yet-to-be-imagined reports of a similarly aggregate and
anonymized nature.
So please install the sysutils/panicmail port and enable it in rc.conf! This
all depends on getting useful data, and I can’t do that without your help.
Речь идёт о пулах в десятки терабайт, которые заполнены данными. Команды zpool/zfs destroy даже не мощном сервере будет выполняться часами, если не днями.
{kind=link}