Сегодня хочу поделиться с вами одним из своих наработанных мануалов, который отточен многоразовым применением, про который с уверенностью могу сказать, что «точно работает!» без лишних танцев с бубном.
Ориентирована статья скорее на начинающих системных администраторов, чем на гуру (для них тут ничего нового нет 🙂 ), и в ней я постараюсь раскрыть рабочий и довольно быстрый вариант развертывания сервера виртуальных машин, стараясь при этом охватись как можно больше нюансов и подводных камней.
Однако, буду рад вниманию знающих и опытных админов, которые, возможно, дадут дельные советы и помогут поправить ошибки, если таковые имеются.
Начнем с того, что если Вы читаете это, то у вас уже готова ОС CentOS 6 (я использовал версию 6.3), причем для установки гостевых ВМ разной битности (32 или 64), хост-сервер (физический сервер, на котором и будем устанавливать KVM вместе с ВМ) должен быть именно с 64-битной ОС.
Все действия выполняются из-под пользователя root.
Итак, приступим к руководству.
1. Шаг — Подготовка
Посмотрим информацию по процессору
# cat /proc/cpuinfo | egrep "(model name|flags)"
Некоторые флаги
1. HT — Hyper-Threading support
Реализация технологии одновременной мультипоточности. Технология увеличивает производительность процессора при определённых рабочих нагрузках. Если включена, то система определяет два логических процессора на один физический процессор (ядро). Присутствует исключительно в сериях процессоров Intel Xeon, Pentium 4, Atom, Core i3, Core i5, Core i7.
2. LM — Long Mode (x86-64 support)
Грубо говоря, если указана, процессор выполнен по 64-битной технологии (также имеет названия: x86-64, x64, AMD64, Intel64, EM64T). Это расширение архитектуры x86 с полной обратной совместимостью. В процессорах Intel поддержка появилась с поздних Pentium 4, у AMD — c Athlon64.
3. VMX (Intel), SVM (AMD) — Hardware virtualization support
Поддержка процессором технологий Intel VT-x или AMD-V означает наличие дополнительных инструкций для предоставления прямого доступа к ресурсам процессора из гостевых систем. Позволяет приблизить производительность гостевых систем к реальным и сократить затраты производительности на поддержание хостовой платформы. В настоящий момент Virtual Machine Extensions поддерживается во многих процессорах Intel & AMD, хотя подобные расширения имеют и другие процессорные архитектуры, например, Cell.
4. SSE*, SSSE*, XMM*, 3DNow!, MMX и пр.
Различные наборы инструкций для процессоров. Широко используются компиляторами в целях оптимизации кода под конкретную архитектуру.
5. AES — Intel Advanced Encryption Standard
Этот довольно спорный набор инструкций увеличивает производительность при кодировании/декодировании AES, присутствующий только у серии Intel Xeon. Часто используется фанатами Intel для подкрепления крутизны серверной линейки CPU, хотя довольно известен тот факт, что процессоры AMD более сильны в криптовании данных, например, в алгоритме SHA.
Проверяем, поддерживает ли CPU аппаратную виртуализацию:
#egrep '(vmx|svm)' --color=always /proc/cpuinfo
Если вывод не пустой и искомые флаги подсвечены цветом, значит — процессор поддерживает аппаратную виртуализацию.
Кому интересно, все действия выполнялись на конфигурации Intel Xeon Quad Core E3-1230 3.20 GHz / 8GB / 2x 1TB.
Устанавливаем KVM и библиотеки виртуализации:
# apt-get install qemu-kvm libvirt-bin virtinst uml-utilities
теперь нужно вклчючить возможность форвардинга и проксирования arp запросов
#sudo sysctl net.ipv4.conf.all.forwarding=1
#sudo sysctl net.ipv4.conf.all.proxy_arp=1
добавим в /etc/sysctl.conf
echo 'net.ipv4.conf.all.forwarding=1' >> /etc/sysctl.conf
echo 'net.ipv4.conf.all.proxy_arp=1' >> /etc/sysctl.conf
и применить их
#sysctl -p
Запускаем сервис KVM
# service libvirtd start
Смотрим, загружен ли модуль KVM
# lsmod | grep kvm
Должны получить вывод:
kvm_intel 52890 16
kvm 314739 1 kvm_intel
В данном случае видим, что загружен модуль kvm_intel, так как произволитель CPU — Intel.
Проверка подключения к KVM
# virsh sysinfo
Должны получить вывод:
<sysinfo type='smbios'>
<bios>
<entry name='vendor'>HP</entry>
<entry name='version'>J01</entry>
.....
2. Шаг — Создание хранилища для виртуальных машин (Storage Pool)
[urlspan]Здесь[/urlspan] приводится описание, как настроить хранилище разных видов.
В рассматриваемом же примере описан простой тип хранилища — для каждой ВМ создается свой файл *.img под виртуальный жесткий диск (или диски — если добавить их несколько), размещены они будут в директории /guest_images.
Только у нас эта директория будет точкой монтирования отдельного жесткого диска хост-сервера, специально отведенного для этих нужд.
Безопасность сохранения данных и то, что нужно создавать как минимум зеркальный raid массив, чтобы не потерять данные ВМ в случае сбоя жесткого диска, мы не будем, так как это — отдельная тема.
Просмотрим список физических дисков на хост-сервере:
# fdisk -l
Получился вывод:
Disk /dev/sda: 1000.2 GB, 1000204886016 bytes
......
Disk /dev/sdb: 1000.2 GB, 1000204886016 bytes
......
На жестком диске sda установлена ОС, его не трогаем, а вот на sdb создаем раздел на все свободное место диска с файловой системой ext4:
(более подробно про следующие операции можно почитать [urlspan]здесь[/urlspan])
Выбираем диск для редактирования
# fdisk /dev/sdb
Создаем новый раздел
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
Сохраняем изменения
Command (m for help): w
The partition table has been altered!
Создаем файловую систему ext4 на всем свободном месте диска /dev/sdb
# mkfs.ext4 /dev/sdb1
Создаем точку монтирования нашего жесткого диска для файлов виртуальных машин:
# mkdir /cd_images
# chmod 700 /cd_images# ls -la /cd_images
total 8
drwx------. 2 root root 4096 May 28 13:57 .
dr-xr-xr-x. 26 root root 4096 May 28 13:57 ..
//***************В разработке*****************************//
Многие советуют отключить вообще [urlspan]Selinux[/urlspan], однако мы выберем иной путь. Мы настроим его правильно.
<span class="comment"># semanage fcontext -a -t virt_image_t /cd_images</span>
Если выполнение этой команды не будет успешным, надо установить дополнительный пакет. Сначала узнаем, какой пакет предоставляет данную команду
# yum provides /usr/sbin/semanage
Получим вывод:
Loaded plugins: rhnplugin
policycoreutils-python-2.0.83-19.8.el6_0.x86_64 : SELinux policy core python utilities
Repo : rhel-x86_64-server-6
Matched from:
Filename : /usr/sbin/semanage
policycoreutils-python-2.0.83-19.1.el6.x86_64 : SELinux policy core python utilities
Repo : rhel-x86_64-server-6
Matched from:
Filename : /usr/sbin/semanage
Устанавливаем policycoreutils-python
# yum -y install policycoreutils-python
После этого снова:
# semanage fcontext -a -t virt_image_t /vm/cd_images (/vm/kvmcd)
//********************************************//
Смонтируем раздел /dev/sdb1 в /vm/kvmcd
# mount -t ext4 /dev/sdb1 /vm/kvmcd
Отредактируем файл /etc/fstab для того, чтобы при перезагрузке хост-сервера раздел с ВМ монтировался автоматически
# mcedit /etc/fstab
Добавляем строку по примеру тех, что уже имеются в файле
/dev/sdb1 /vm/kvmcd ext4 defaults 1 1
Сохраняем файл и продолжаем создание хранилища:
# virsh pool-define-as cd_images dir localhost /vm/kvmcd /dev/sdb1 cd_image /vm/kvmcd
Pool cd_images defined
или
# virsh pool-define-as cd_images dir ---- --target /var/lib/libvirt/images/cd
Проверяем, создалось ли оно:
# virsh pool-list --all
Name State Autostart
-----------------------------------------
default active yes
cd_images inactive no
Далее:
# virsh pool-build cd_images
Pool cd_images built
Запускаем хранилище:
# virsh pool-start cd_images
Pool cd_images started
# virsh pool-list --all
Name State Autostart
-----------------------------------------
default active yes
cd_images active no
Добавляем в автозагрузку:
# virsh pool-autostart cd_images
Pool guest_images_dir marked as autostarted
# virsh pool-list --all
Name State Autostart
-----------------------------------------
default active yes
cd_images active yes
Проверяем:
# virsh pool-info cd_images
3. Шаг — Настройка сети на хост-сервере
!!! ВАЖНО!!!
# apt-get install bridge-utils
Положим, что для выхода «в мир» использовался интерфейс eth0 и он был соответствующим образом настроен.
На нем настроен IP-адрес 10.110.10.15 из /24 сети, маска — 255.255.255.0, шлюз 10.110.10.1.
Продолжаем, создаем сетевой интерфейс типа «bridge» на хост-сервере
# mcedit /etc/network/interfaces
Содержимое файла
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
allow-hotplug eth0
#iface eth0 inet static
iface eth0 inet manual
auto kvmbr0
iface kvmbr0 inet static
address 172.16.174.248
netmask 255.255.255.0
network 172.16.174.0
broadcast 172.16.174.255
gateway 172.16.174.1
bridge_ports eth0
# dns-* options are implemented by the resolvconf package, if installed
dns-nameservers 172.16.174.3
dns-search adminunix.ru
!!! Важно!!!
DEVICE=«eth0» Имя интерфейса должно остаться таким, как было в системе. Если у вас для выхода в Интернет использовался интерфейс eth1, тогда редактировать надо его.
Когда проверили все, перезагружаем сеть:
# service network restart
Проверяем состояние подключения типа «bridge»:
# brctl show
Получаем что-то вроде этого
bridge name bridge id STP enabled interfaces
kvmbr0 8000.0007e92a9957 no eth0
Делаем настройки в iptables, чтобы трафик виртуалок «ходил» через соединение типа bridge
# iptables -I FORWARD -m physdev --physdev-is-bridged -j ACCEPT
# service iptables save
# service iptables restart
Опционально: можно улучшить быстродействие соединения bridge, поправив настройки в /etc/sysctl.conf
sudo sysctl net.ipv4.conf.all.forwarding=1
#sudo sysctl net.ipv4.conf.all.proxy_arp=1
После этого
# sysctl -p /etc/sysctl.conf
#/etc/init.d/libvirt-bin restart
4. Шаг — Установка новой виртуальной машины
Установка CentOS на гостевую ВМ:
virt-install -n VMName_2 --ram 1024 --arch=x86_64
--vcpus=1 --cpu host --check-cpu
--extra-args="vnc sshd=1 sshpw=secret ip=static reboot=b selinux=0"
--os-type linux --os-variant=rhel6 --boot cdrom,hd,menu=on
--disk pool=guest_images_dir,size=50,bus=virtio
--network=bridge:br0,model=virtio
--graphics vnc,listen=0.0.0.0,keymap=ru,password=some.password.here
--noautoconsole --watchdog default,action=reset --virt-type=kvm
--autostart --location http://mirror.yandex.ru/centos/6.3/os/x86_64/
Примечание 1:
VMName_2 — имя новой виртуальной машины
–ram 1024 — кол-во виртуальной памяти
–arch=x86_64 — архитектура ОС виртуалки
–vcpus=1 — кол-во виртуальных процессоров
–os-type linux — тип ОС
–disk pool=guest_images_dir,size=50 — размещение хранилища, размер вирт. диска
–network=bridge:br0
Примечание 2:
Если на ВМ нужна «белая сеть», тогда ставим
--network=bridge:br0
Если на ВМ требуется «серая сеть», тогда ставим
--network=bridge:virbr0
В этом случае для ВМ будет присвоен серый IP по DHCP от хост-сервера.
--graphics vnc,listen=0.0.0.0,keymap=ru,password=some.password.here
Тут указываем пароль для подключения к ВМ по vnc
Установка Windows на гостевую ВМ:
virt-install --connect qemu:///system --arch=x86_64
-n VMName_1 -r 1024 --vcpus=1
--disk pool=guest_images_dir,size=50,bus=virtio,cache=none
-c /iso/Windows2008R2RU.ISO --graphics vnc,listen=0.0.0.0,keymap=ru,password=some.password.here
--noautoconsole --os-type windows --os-variant win2k8
--network=bridge:br0,model=e1000 --disk path=/iso/virtio-win.iso,device=cdrom,perms=ro
Примечание:
Параметры такие же, как и в примере с установкой CentOS. Но есть различия.
При установке ОС Windows не увидит виртуального жесткого диска, поэтому надо подгрузить дополнительный виртуальный cdrom с драйверами /iso/virtio-win.iso — расположение файла ISO с драйверами виртуального диска. Взять можно отсюда.
Выполняем команду на установку новой ВМ, затем подключаемся по [urlspan]vnc[/urlspan] к хост-серверу для продолжения установки ОС. Для того, чтобы узнать порт для подключения, выполняем:
# netstat -nltp | grep q
tcp 0 0 0.0.0.0:5900 0.0.0.0:* LISTEN 64141/qemu-kvm
tcp 0 0 0.0.0.0:5903 0.0.0.0:* LISTEN 63620/qemu-kvm
tcp 0 0 0.0.0.0:5904 0.0.0.0:* LISTEN 6971/qemu-kvm
tcp 0 0 0.0.0.0:5905 0.0.0.0:* LISTEN 57780/qemu-kvm
При установке новой ВМ, порт vnc-сервера увеличится на 1. При удалении ВМ, порт освобождается,
и затем выдается новой ВМ. То есть, номер порта последней ВМ не обязательно самый большой из 590…
Чтобы узнать, на каком порту vnc виртуалка с определенным названием, вводим:
# virsh vncdisplay VMName_1
:3
где VMName_1 — имя ВМ, :3 — номер по порядку порта, начиная с 5900, то есть подключаться надо на порт 5903, но в программе UltraVNC сработает и так 10.110.10.15:3

Примечание
Если при создании ВМ вылетает ошибка Permission denied, kvm не может открыть файл диска ВМ *.img,
значит, надо разрешить выполнение действий qemu-kvm из-под root (предполагается, что управление
ВМ производится из-под специально созданного для этих целей пользователя, например, libvirt). Но мы обойдемся и пользователем root.
Поправляем конфиг:
# vi /etc/libvirt/qemu.conf
Находим и раскомментируем в нем строки:
# The user ID for QEMU processes run by the system instance.
user = "root"
# The group ID for QEMU processes run by the system instance.
group = "root"
Полезно знать:
Конфиги ВМ находятся здесь /etc/libvirt/qemu/
Для того, чтобы отредактировать параметры (добавить процессор, ОЗУ или еще что-то),
ищем конфиг ВМ с нужным названием, редактируем:
# vi /etc/libvirt/qemu/VMName_1.xml
К примеру, можно указать статический порт vnc для конкретной ВМ, чтобы всегда подключаться к нужному порту
<graphics type='vnc' port='5914' autoport='no' listen='0.0.0.0' passwd='some.password.here'>
<listen type='address' address='0.0.0.0'/>
</graphics>
Теперь у этой ВМ порт vnc будет — 5914. Не забудьте перезагрузить libvirtd для применения изменений. Саму ВМ тоже следует перезагрузить. Поэтому изменяйте конфигурационный файл ВМ пока она выключена, далее выполняйте service libvirtd reload, затем стартуйте ВМ.
Команды для управления ВМ:
virsh -c qemu:///system help
Встроенная помощь по командам
virsh -c qemu:///system list --all
Посмотреть статус установленных ВМ
virsh -c qemu:///system start vsrv1
Запусить ВМ vsrv1
virsh -c qemu:///system shutdown vsrv1
Послать команду завершения работы ВМ
virsh -c qemu:///system destroy vsrv1
Принудительно завершить работу ВМ
virsh -c qemu:///system undefine vsrv1
Удалить ВМ
5. Шаг — Настройка сети в случае «серых» IP-адресов в ВМ
Если на 4 шаге вы выбрали серую сеть для новой ВМ (--network=bridge:virbr0), то надо выполнить следующие действия (на хост-сервере!) для проброса трафика на ВМ
Разрешить форвардинг трафика на уровне ядра ОС:
# sysctl net.ipv4.ip_forward=1
# iptables -I FORWARD -j ACCEPT
# iptables -t nat -I PREROUTING -p tcp -d 10.110.10.15 --dport 5910 -j DNAT --to-destination 192.168.122.170:5901
Здесь 10.110.10.15 — белый (внешний) IP хост-сервера. 192.168.122.170 — серый IP-адрес гостевой ОС.
# iptables -t nat -I POSTROUTING -p tcp -s 192.168.122.170 --sport 5901 -j SNAT --to-source 10.110.10.15:5910
На примере установки ОС CentOS на гостевой машине, когда установка перешла в графический режим, и предлагает подключиться на локальный порт 5901 гостевой ОС.
Подключаемся из ПК, за которым сидите, по vnc к 10.110.10.15:5910 или 10.110.10.15:10 тоже сработает в UltraVNC.
По такому же принципу можно прокинуть порт (стандартный) RDP 3389 или SSH 22 в гостевую ОС.
6. Шаг — Подготовка к управлению виртуальными машинами удаленного сервера с удобным графическим интерфейсом (используя virt-manager)
Есть много способов «прокинуть» графику удаленного сервера на ПК, за которым выполняете действия администрирования. Мы остановимся на ssh-туннелировании.
Положим, что вы выполняете действия с локального ПК под управлением Windows (в операционных системах под управлением Linux сделать это куда легче :), нужно выполнить всего одну команду ssh -X username@12.34.56.78, конечно, с оговоркой, что на удаленном сервере X11 forwarding разрешен и вы сидите за локальным Linux ПК c графической оболочкой), тогда нам необходимо
1. Всем знакомый PuTTY,
2. Порт сервера X для Windows — Xming
3. В настройках PuTTY включить «Enable X11 Forwarding»
Сделать, как показано на картинке:
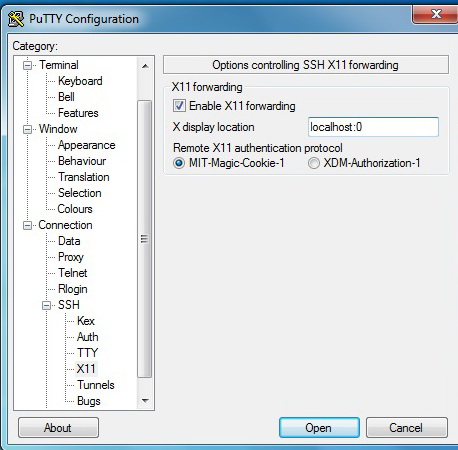
В момент подключения к удаленному серверу Xming должен быть уже запущен.
На хост-сервере с CentOS для SSH включить X11 Forwarding, для этого отредактируйте файл sshd_config:
# mcedit /etc/ssh/sshd_config
X11Forwarding yes
X11DisplayOffset 10
X11UseLocalhost yes
После этого
# /etc/init.d/sshd restart
Устанавливаем virt-manager на хост-сервере:
# apt-get install virt-manager
Еще один компонент
# apt-get install xorg-x11-xauth
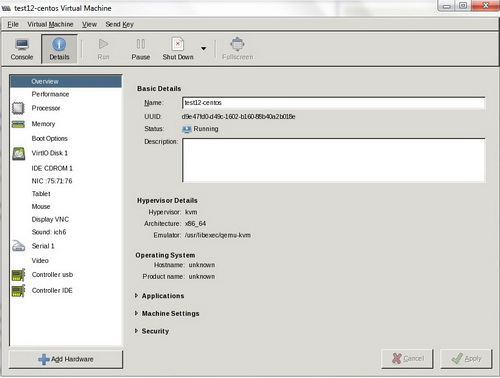
7. Шаг — Непосредственный запуск virt-manager
После этого надо перезайти по SSH к удаленному серверу. Xming должен быть запущен.
Запускаем графическую утилиту управления виртуальными машинами
# virt-manager
Откроется окно virt-manager

Консоль управления ВМ

Конфигурация ВМ и ее изменение
Надеюсь, читателю понравилась статья. Лично я, прочитай бы подобную в своё время, резко сократил бы потраченное время на то, чтобы перелопатить множество мануалов от разных админов, для разных ОС; сохранил бы кучу времени, потраченное на гугление, когда появлялись все новые и новые нюансы.
{kind=link}