# Основан на конфигурационных файлах сервера NCSA,
# написанных Rob McCool.
#
# Это главный конфиг-файл сервера Apache,
# содержащий директивы, управляющие
# работой сервера. За более подробной информацией об этих директивах,
# обращайтесь по адресу <URL:http://httpd.apache.org/docs-2.0/>
#
# Не стоит читать приведенные здесь команды, не вникая в их суть. Здесь
# они служат лишь в качестве примера или шпаргалки. Если вы не
# уверены — обращайтесь к онлайновой документации. Вы предупреждены.
#
# Конфигурационные директивы сгруппированы в три основные разделы :
#
# 1. Директивы, управляющие серверным процессом Apache в целом
# («глобальная среда»).
#
# 2. Директивы, определяющие параметры «главного»
# или дефолтного сервера,
# который отвечает на запросы, не обрабатываемые каким-либо
# виртуальным хостом. Эти директивы также задают дефолтные
# установки для всех виртуальных хостов.
#
# 3. Установки для виртуальных хостов, позволяющие единым серверным
# процессом Apache обрабатывать веб-запросы, на самом деле
# адресованные различным хостам (по имени хоста или по IP).
#
# Наименования конфиг- и лог-файлов : Если имя файла начинается с «/» (или c
# «диск:/» под Win32) — сервер использует явно указанный путь. Если же имя
# НЕ начинается с «/», то к нему префиксируется значение ServerRoot.
# Т.о., если ServerRoot="/usr/local/apache", то «logs/foo.log» сервер
# интерпретирует как «/usr/local/apache/logs/foo.log»
#
#
# ПРИМЕЧАНИЕ: При определении имен файлов необходимо использовать прямые
# слэши вместо обратных (т.е. «c:/apache» вместо «c:apache»).
# Если диск не указан, по умолчанию используется тот, на котором размещен
# Apache.exe. Для однозначности, все же, рекомендуется в абсолютных путях
# всегда четко указывать диск.
#
#
### Раздел 1: Глобальная среда
#
# Директивы в этом разделе задают общие параметры работы Apache, такие, как,
# например, максимальное число одновременных запросов или
# месторасположение конфиг файлов.
#
# ServerRoot: Вершина дерева директорий, в которых содержатся конфиг- , лог- и
# error-файлы.
#
# ПРИМЕЧАНИЕ : Если это дерево будет располагаться на томе монтируемой
# файловой системы NFS (или на другом сетевом ресурсе),
# просьба прочесть описание директивы LockFile
# (по адресу <URL:http://httpd.apache.org/docs-2.0/mod/core.html#lockfile>)
# — во избежание массы проблем.
#
# В конце строки добавлять слэш НЕ следует.
#
ServerRoot "E:/Apache2"
#
# ScoreBoardFile: Файл для хранения информации внутреннего процесса сервера.
# Если не указан (по дефолту не указан), то эта информация хранится в
# неименованном разделе общей памяти, и не доступна посторонним программам.
# Если же файл указан, то он должен быть уникальным для каждой отдельной
# инстанции Apache. Этот файл должен располагаться на МЕСТНОМ диске.
#
#ScoreBoardFile logs/apache_runtime_status
#
# Файл записи идентификационного номера процесса (PID) сервера при запуске.
#
PidFile logs/httpd.pid
#
# Timeout: Время ожидания в секундах, прежде чем попытки приема или отправления
# выдают сообщение о тайм-ауте.
#
Timeout 300
#
# KeepAlive: Допускаются ли персистентные соединения (см. примечания).
# Для запрета укажите «Off».
#
KeepAlive On
#
#
# MaxKeepAliveRequests: Максимальное количество запросов при одном
# персистентном соединении. Значение 0 снимает ограничения. Для максимального
# быстродействия рекомендуем высокое значение.
#
MaxKeepAliveRequests 100
#
# KeepAliveTimeout: Время ожидания (в секундах) следующего запроса от того же
# клиента в рамках одного персистентного соединения
#
KeepAliveTimeout 15
#
#
# Server-Pool Size Regulation (MPM specific)
#
# Установка размеров серверного пула. Параметры данного подраздела
# меняются в зависимости от конкретного модуля мультизадачного режима
# (MPM — Multi-Processing Module), который, в свою очередь, меняется в
# зависимости от конкретной базовой ОС.
#
# WinNT MPM
# ThreadsPerChild: constant number of worker threads in the server process
# MaxRequestsPerChild: maximum number of requests a server process serves
#
# WinNT MPM : Мультизадачный модуль для Win32
# ThreadsPerChild: Постоянное число рабочих нитей (тредов) в серверном(sic)
# процессе
# MaxRequestsPerChild: Максимальное количество запросов, обслуживаемых
# серверным(sic) процессом
#
# (В обоих случаях, речь, на самом деле, идет о дочерних процессах сервера,
# а не о самом серверном процессе. Дело в том, что в случае Win32, который
# как раз здесь рассматривается, запускается один лишь единственный дочерний
# процесс, поэтому для WinNT_MPM эти понятия, в некоторой степени,
# совпадают -пп)
#
<IfModule mpm_winnt.c>
ThreadsPerChild 250
MaxRequestsPerChild 0
</IfModule>
#
# Listen: Позволяет привязать Apache к конкретным адресам IP и/или портам,
# помимо(sic) дефолтных. См. также директиву <VirtualHost>.
#
# Следует поменять это на конкретные адреса IP (как показано ниже), чтобы
# Apache не «прилипал» ко всем привязанным адресам (0.0.0.0)
#
# (Автор здесь немного противоречит себе. Возможно, правильнее второй абзац,
# а первый просто остался по наследству от предыдущих версий. Следует
# отметить, что в отличии от предыдущих версий, директива Listen теперь
# является обязательной — без нее Apache стартовать не будет -пп).
#
#Listen 12.34.56.78:80
Listen 80
#
#
# Поддержка динамических, разделяемых объектов (DSO, Dynamic Shared Object)
#
# Для того, чтобы использовать модули, созданные как DSO, следует поместить
# здесь соответствующие строки с директивой «LoadModule», чтобы команды этого
# модуля были доступны ДО обращения к ним. Статически скомпилированные модули
# (выявляемые по команде «httpd -l») в этом не нуждаются.
#
# Пример:
# LoadModule foo_module modules/mod_foo.so
#
LoadModule access_module modules/mod_access.so
LoadModule actions_module modules/mod_actions.so
LoadModule alias_module modules/mod_alias.so
LoadModule asis_module modules/mod_asis.so
LoadModule auth_module modules/mod_auth.so
#LoadModule auth_anon_module modules/mod_auth_anon.so
#LoadModule auth_dbm_module modules/mod_auth_dbm.so
#LoadModule auth_digest_module modules/mod_auth_digest.so
LoadModule autoindex_module modules/mod_autoindex.so
#LoadModule cern_meta_module modules/mod_cern_meta.so
LoadModule cgi_module modules/mod_cgi.so
#LoadModule dav_module modules/mod_dav.so
#LoadModule dav_fs_module modules/mod_dav_fs.so
LoadModule dir_module modules/mod_dir.so
LoadModule env_module modules/mod_env.so
#LoadModule expires_module modules/mod_expires.so
#LoadModule file_cache_module modules/mod_file_cache.so
#LoadModule headers_module modules/mod_headers.so
LoadModule imap_module modules/mod_imap.so
LoadModule include_module modules/mod_include.so
#LoadModule info_module modules/mod_info.so
LoadModule isapi_module modules/mod_isapi.so
LoadModule log_config_module modules/mod_log_config.so
LoadModule mime_module modules/mod_mime.so
#LoadModule mime_magic_module modules/mod_mime_magic.so
#LoadModule proxy_module modules/mod_proxy.so
#LoadModule proxy_connect_module modules/mod_proxy_connect.so
#LoadModule proxy_http_module modules/mod_proxy_http.so
#LoadModule proxy_ftp_module modules/mod_proxy_ftp.so
LoadModule negotiation_module modules/mod_negotiation.so
#LoadModule rewrite_module modules/mod_rewrite.so
LoadModule setenvif_module modules/mod_setenvif.so
#LoadModule speling_module modules/mod_speling.so
#LoadModule status_module modules/mod_status.so
#LoadModule unique_id_module modules/mod_unique_id.so
LoadModule userdir_module modules/mod_userdir.so
#LoadModule usertrack_module modules/mod_usertrack.so
#LoadModule vhost_alias_module modules/mod_vhost_alias.so
#LoadModule ssl_module modules/mod_ssl.so
#
# Директива ExtendedStatus определяет, будет ли Apache выдавать подробную
# информацию о состоянии (ExtendedStatus On), или только общую справку
# (ExtendedStatus Off), при обращении к функции «server-status». Значение по
# умолчанию — Off.
#
#ExtendedStatus On
#
#
### Раздел 2: Конфигурация «главного» (дефолтного) сервера
#
# Директивы этого раздела устанавливают значения, используемые «главным
# сервером», который отвечает на запросы, не обрабатываемые виртуальными
# хостами. Эти значения также задают дефолты для любых последующих
# контейнеров <VirtualHost> в этом файле.
#
# Любые из этих директив могут быть включены в контейнер <VirtualHost>; в таком
# случае дефолтные установки будут переопределены для этого виртуального хоста.
#
# ServerAdmin: Ваш адрес, по которому следует направлять сообщения о проблемах
# с сервером. Этот адрес появится на некоторых сгенерированных сервером
# страницах, таких, как сообщения об ошибках. Пример: admin@your-domain.com
#
ServerAdmin admin@admin.com
#
# Директива ServerName задает имя и порт, которыми сервер представляется.
# Это часто может быть определено автоматически, но рекомендуется явно задавать
# эти параметры, во избежание проблем при запуске.
#
# Если Servername не указывает на действительное DNS-имя вашего хоста,
# переадресация, сгенерированная сервером, не будет работать. См. также
# директиву UseCanonicalName
#
# Если ваш хост не имеет зарегистрированного DNS-имени, укажите здесь его IP.
# В любом случае вам придется обращаться к нему по адресу, при этом
# переадресация станет разумней.
#
ServerName server:80
#
# UseCanonicalName: Определяет как Apache строит внутренние URL-ссылки и
# значения переменных SERVER_NAME и SERVER_PORT. Когда задано «Off», Apache
# использует имя и порт, данные клиентом. Если же задано «On», то Apache
# использует значение директивы ServerName.
#
UseCanonicalName Off
#
# DocumentRoot: Директория, из которой будут выдаваться ваши документы.
# По умолчанию, все запросы обслуживаются из этой директории, но могут быть
# использованы символические линки (пересылки) и алиасы (псевдонимы) для
# указания других мест.
#
DocumentRoot "E:/Apache2/htdocs"
#
#
# Каждая доступная для Apache директория может быть сконфигурирована в
# отношении действий и сервисов, которые разрешены и/или запрещены в
# этой директории (и ее суб-директориях).
#
# Для начала, мы определяем «дефолт», как весьма ограниченный набор разрешений.
#
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
#
# Заметьте, что в дальнейшем вы должны явно разрешать конкретные действия так
# что, если что-то не работает так, как вы ожидаете, убедитесь, что вы явно
# разрешили это ниже.
#
# Здесь должна быть указана директория, которую вы установили как DocumentRoot.
#
<Directory "E:/Apache2/htdocs">
#
# Опции могут иметь значения «None», «All» или любую комбинацию из :
# «Indexes», «Includes», «FollowSymLinks», «SymLinksifOwnerMatch», «ExecCGI»,
# и «Multiviews».
#
# Заметьте, что опция «MultiViews» должна быть ЯВНО указана — т.к.
# «Options All» ее НЕ включает.
#
# Директива Options является и сложной и важной. Для дополнительной информации
# см. «http://httpd.apache.org/docs-2.0/mod/core.html#options»
#
Options Indexes FollowSymLinks
#
# AllowOverride определяет какие директивы могут быть использованы в файлах
# .htaccess. Она может принимать значения «All», «None», или любую
# комбинацию из : «Options», «FileInfo», «AuthConfig», и «Limit»
#
AllowOverride None
#
# Эти директивы определяют, кто может получать материал с этого сервера.
#
Order allow,deny
Allow from all
</Directory>
#
#
# UserDir: Имя директории, которое постфиксируется к имени домашней директории
# пользователя при получении запроса ~user. Будьте особенно внимательны — здесь
# используются прямые слеши.
#
UserDir "My Documents/My Website"
#
# Управляет доступом к директориям UserDir. Приведен пример сайта, где эти
# директории имеют ограничение «read-only» (только чтение).
#
# Исправьте (в следующем) корневой путь, чтобы он соответствовал
# местонахождению директории пользователя в вашей системе, например,
# «C:/WinNT/profiles/*/My Documents/My Website».
#
#<Directory «C:/Documents and Settings/*/My Documents/My Website»>
# AllowOverride FileInfo AuthConfig Limit
# Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec
# <Limit GET POST OPTIONS PROPFIND>
# Order allow,deny
# Allow from all
# </Limit>
# <LimitExcept GET POST OPTIONS PROPFIND>
# Order deny,allow
# Deny from all
# </LimitExcept>
#</Directory>
#
#
# DirectoryIndex: Имя файла, выдаваемого Apache в ответ на запрос директории.
#
# Файл «index.html.var» (типа type-map или application/x-type-map) используется
# для выдачи конкретной разновидности многовариантного документа в зависимости
# от параметров запроса (content-negotiated). Опция MultiViews может служить
# той же цели, но она намного медленее.
#
DirectoryIndex index.html index.html.var
#
# AccessFileName: Имя файла в каждой директории, задающего правила доступа (к
# этой директории). См. также директиву AllowOverride.
#
AccessFileName .htaccess
#
# Следующие строки запрещают просмотр файлов «.htaccess» и «.htpasswd»
# со стороны Web-клиентов.
#
<Files ~ "^.ht">
Order allow,deny
Deny from all
</Files>
#
# TypesConfig опеределяет местонахождение файла «mime.type» (или ему
# эквивалентного).
#
TypesConfig conf/mime.types
#
#
# Директива DefaultType — это дефолтный MIME-тип, используемый сервером для
# документов, тип которых не определяем по иным признакам, таким, как
# расширение имени файла. Если ваш сервер содержит в основном текстовые или
# HTML-документы, «text/plain» является подходящим значением. Если большая
# часть представляет собой бинарные файлы, такие, как программы или
# изображения, возможно использование «application/octet-stream», чтобы
# предотвратить попытки браузеров показывать содержимое двоичных файлов как
# текст.
#
DefaultType text/plain
#
#
# Модуль «mod_mime_magic» позволяет серверу использовать различные приемы для
# определения типа файла по его содержанию. Директива MIMEMagicFile указывает
# этому модулю месторасположение (файла с описаниями) этих приемов.
#
<IfModule mod_mime_magic.c>
MIMEMagicFile conf/magic
</IfModule>
#
#
# HostnameLookups определяет, записывать ли имена клиентов, или только их
# IP-адреса, например, «www.apache.org» («On») или «204.62.129.132»(«Off»).
# По дефолту «Off», поскольку в целом для Интернета было бы лучше, если бы
# эта опция включалась сознательно, т.к. ее включение означает, что каждый
# клиентский запрос влечет за собой КАК МИНИМУМ еще один обратный запрос к
# серверу имен.
#
HostnameLookups Off
#
# ErrorLog: Расположение error-файла. Если вы не задаете директиву ErrorLog
# внутри контейнера какого-либо <VirtualHost>, его сообщения об ошибках
# будут записаны здесь. Если же вы определите error-файл для какого-либо
# <VirtualHost>, то его сообщения об ошибках будут записываться там, а не здесь.
#
ErrorLog logs/error.log
#
#
# LogLevel: Control the number of messages logged to the error.log.
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
#
# LogLevel: Определение количества(sic) ошибок, которые записываются в
# error.log. Возможные значения :
# «debug», «info», «notice», «warn», «error», «crit», «alert», и «emerg».
#
LogLevel warn
#
# Следующие директивы присваивают имена некоторым определениям
# форматов записей, для использования в директиве
# CustomLog (см. ниже).
#
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"" combined
LogFormat "%h %l %u %t "%r" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
# (слово access — здесь как запрос о доступе, а не как доступ — пп)
#
# Расположение и формат лог-файла запросов (в общем формате лог-файлов —
# Common Logfile Format). Если вы не определяете никаких лог-файлов запросов
# внутри контейнера какого-либо <VirtualHost>, сведения будут записываться
# здесь. Если же вы определяете отдельные лог-файлы запросов для каждого(sic)
# <VirtualHost>, то транзакции будут отслеживаться там, а не здесь.
#
# (Наверное, здесь имеется в виду «для отдельных» <VirtualHost>, а не
# «для каждого» -пп)
#
CustomLog logs/access.log common
#
#
# Если вы хотите иметь лог-файлы для отслеживания значений agent и referrer
# (из соответствующих полей поступающих запросов -пп), раскомментируйте
# следующие директивы.
#
#CustomLog logs/referer.log referer
#CustomLog logs/agent.log agent
#
# Если вы предпочитаете единый лог-файл с информацией о запросе, агенте и
# referrer (комбинированный формат лог-файла — Combined Logfile Format),
# вы можете использовать следующую директиву.
#
#CustomLog logs/access.log combined
#
#
# Добавить дополнительную строчку, содержащую версию сервера и имя виртуального
# хоста на страницах, сгенерированных сервером (таких, как сообщения об
# ошибках, FTP листинги директорий, выдачи модулей «mod_status» и «mod_info»
# и т.п.; документы, сгенерированные скриптами CGI, к ним не относятся).
# Установите «EMail», чтобы включить еще и линк «mailto:», направленный
# на ServerAdmin.
# Допустимые значения: On | Off | Email
#
ServerSignature On
#
#
# Алиасы (Псевдонимы): Можно добавлять любое количество алиасов (без
# ограничений). Формат: Alias псевдоним действительное_имя
#
# Обратите внимание, что если вы включаете завершающий слэш в псевдониме, то
# сервер потребует его наличия и в URL. Так, псевдоним «/icons» не определен в
# данном примере, только «/icons/». Если псевдоним закначивается на слеш,
# действительное_имя также должно заканчиваться на слеш, а если псевдоним его
# опускает, то и действительное_имя его должно опустить.
#
# Мы используем алиас «/icons/» для листингов директорий типа FancyIndexed.
# Можно закомментировать эту часть, если вы не используете FancyIndexing.
#
Alias /icons/ "E:/Apache2/icons/"
<Directory "E:/Apache2/icons">
Options Indexes MultiViews
AllowOverride None
Order allow,deny
Allow from all
</Directory>
#
# Следует поменять это значение на (ваш) ServerRoot/manual/. Данный алиас
# обеспечивает доступ к документации, даже если вы передвините свой
# DocumentRoot. Можно эту часть закомментировать, если документация не нужна.
#
Alias /manual "E:/Apache2/manual"
#
<Directory "E:/Apache2/manual">
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
Allow from all
</Directory>
#
#
# ScriptAlias: Указывает директории, которые содержат серверные скрипты.
# Свойства ScriptAlias-ов в основном такие же, как и у простых Alias-ов,
# кроме того, что при запросе, документы в каталоге «действительное_имя»
# считаются приложениями и выполняются на сервере, а не отправляются
# клиенту. К директиве ScriptAlias применяются те же правила в отношении
# завершающего «/», что и к Alias.
#
ScriptAlias /cgi-bin/ "E:/Apache2/cgi-bin/"
#
# Значение «E:/Apache2/cgi-bin» следует поменять на существующую директорию
# CGI, указанную в ScriptAlias.
#
<Directory "E:/Apache2/cgi-bin">
AllowOverride None
Options None
Order allow,deny
Allow from all
</Directory>
#
# Директива Redirect позволяет сообщить клиенту о документах, ранее
# существовавших в именном пространстве сервера, но теперь не существующих.
# Она позволяет сообщить клиенту новый адрес перемещенного документа.
# Пример:
# «Redirect permanent /foo http://www.example.com/bar»
#
#
# Директивы, управляющие внешним видом листингов директории,
# генерируемых сервером.
#
#
# FancyIndexing задает, хотите ли вы стилизованные листинги директорий или
# же стандартные. VersionSort определяет, будут ли файлы с номерами версий
# сравниваться «естественно», т.е. так, чтобы в листинге файл
# «apache-1.3.9.tar» предшествовал файлу «apache-1.3.12.tar».
#
IndexOptions FancyIndexing VersionSort
#
#
# Директивы AddIcon* указывают серверу, какие иконы показывать для
# различных файлов, или расширений имен файлов. Они показываются только
# для директорий с FancyIndexing.
#
AddIconByEncoding (CMP,/icons/compressed.gif) x-compress x-gzip
AddIconByType (TXT,/icons/text.gif) text/*
AddIconByType (IMG,/icons/image2.gif) image/*
AddIconByType (SND,/icons/sound2.gif) audio/*
AddIconByType (VID,/icons/movie.gif) video/*
AddIcon /icons/binary.gif .bin .exe
AddIcon /icons/binhex.gif .hqx
AddIcon /icons/tar.gif .tar
AddIcon /icons/world2.gif .wrl .wrl.gz .vrml .vrm .iv
AddIcon /icons/compressed.gif .Z .z .tgz .gz .zip
AddIcon /icons/a.gif .ps .ai .eps
AddIcon /icons/layout.gif .html .shtml .htm .pdf
AddIcon /icons/text.gif .txt
AddIcon /icons/c.gif .c
AddIcon /icons/p.gif .pl .py
AddIcon /icons/f.gif .for
AddIcon /icons/dvi.gif .dvi
AddIcon /icons/uuencoded.gif .uu
AddIcon /icons/script.gif .conf .sh .shar .csh .ksh .tcl
AddIcon /icons/tex.gif .tex
AddIcon /icons/bomb.gif core
AddIcon /icons/back.gif ...
AddIcon /icons/hand.right.gif README
AddIcon /icons/folder.gif ^^DIRECTORY^^
AddIcon /icons/blank.gif ^^BLANKICON^^
#
# DefaultIcon показывает какую икону показывать для файлов, не имеющих
# явно определенных икон.
#
DefaultIcon /icons/unknown.gif
#
#
# Директива AddDescription позволяет поместить краткое описание после имени
# файла в листингах, сгенерированных сервером. Они показываются только для
# директорий с FancyIndexing.
#
# Формат: AddDescription «описание» имя_файла
#
#AddDescription «GZIP compressed document» .gz
#AddDescription «tar archive» .tar
#AddDescription «GZIP compressed tar archive» .tgz
#
#
# ReadmeName — это дефолтное имя README-файла, который сервер будет искать по
# умолчанию и добавит в конце листингов директорий.
#
# HeaderName — имя файла, который будет добавлен в начале листингов директорий.
#
ReadmeName README.html
HeaderName HEADER.html
#
#
# IndexIgnore — это список файлов, которые должны быть исключены из
# листингов. В именах файлов допускается использование метасимволов замены в
# стиле shell.
#
IndexIgnore .??* *~ *# HEADER* README* RCS CVS *,v *,t
#
#
# AddEncoding позволяет некоторым браузерам (Mosaic/X 2.1+) на ходу
# распаковывать информацию. Замечание: не все браузеры поддерживают это.
# Несмотря на сходство имен, следующие директивы Add* не имеют ничего общего
# с директивами форматирования FancyIndexing, указанными выше.
#
AddEncoding x-compress Z
AddEncoding x-gzip gz tgz
#
#
# DefaultLanguage и AddLanguage позволяют указать языки документов. Вы можете
# в последствие использовать динамическое определение содержимого (content
# negotiation) для выдачи браузеру файла на языке понятном пользователю.
#
#
# Установка языка default. Это означает, что вся информация, идущая без
# конкретного языкового тэга (см. ниже), будет идти на дефолтном языке.
# Вероятно, не стоит задавать эту директиву, не будучи твердо уверенным в том,
# что она подходит для всех случаев.
#
#
# * В общем, лучше не указывать определенный язык
# * для страницы, чем задать неправильный язык.
#
# DefaultLanguage nl
#
# Примечание 1: Суффикс не обязательно должен совпадать с
# кодом-идентификатором языка. Те, у кого есть документы
# на польском языке (стандартный буквенный
# код Интернета pl), могут воспользоваться директивой
# «AddLanguage pl .po» во избежание конфликта с распространенным
# суффиксом скриптов на языке Perl.
#
# Примечание 2: Нижеследующие примеры показывают, что в некоторых
# случаях двухбуквенный код языка не совпадает с двухбуквенным
# кодом соответствующей страны.
# Например, Датский (da) и Дания (dk).
#
# Примечание 3: В случае «ltz» мы нарушаем требования RFC, используя
# трехбуквенный код. Ведется работа по устранению несоответствий и
# усовершенствованию «rfc1766».
#
# Danish, датский (da)
# Dutch, голландский, (nl)
# English, английский (en)
# Estonian, эстонский (et)
# French, французский (fr)
# German, немецкий (de)
# Greek-Modern, новогреческий (el)
# Italian, итальянский (it)
# Norwegian, норвежский (no)
# Norwegian Nynorsk (nn)
# Korean, корейский (kr)
# Portugese, португальский (pt)
# Luxembourgeois*, люксембургский (ltz)
# Spanish, испанский (es)
# Swedish, шведский (sv)
# Catalan, каталанский (ca)
# Czech, чешский(cz)
# Polish, польский (pl)
# Brazilian Portuguese, бразильско-португальский (pt-br)
# Japanese, японскский (ja)
# Russian, русский (ru)
# Croatian, хорватский (hr)
#
AddLanguage da .dk
AddLanguage nl .<code class="bash functions">nl
AddLanguage en .en
AddLanguage et .et
AddLanguage fr .fr
AddLanguage de .de
AddLanguage he .he
AddLanguage el .el
AddLanguage it .it
AddLanguage ja .ja
AddLanguage pl .po
AddLanguage kr .kr
AddLanguage pt .pt
AddLanguage nn .nn
AddLanguage no .no
AddLanguage pt-br .pt-br
AddLanguage ltz .ltz
AddLanguage ca .ca
AddLanguage es .es
AddLanguage sv .se
AddLanguage cz .cz
AddLanguage ru .ru
AddLanguage tw .tw
AddLanguage zh-tw .tw
AddLanguage hr .hr
#
# LanguagePriority позволяет задать порядок выбора некоторых языков (в случае
# неоднозначности) при динамическом определении содержания (content
# negotiation).
#
# Просто перечислите языки в порядке убывания приоритета. Здесь они даны в
# более-менее алфавитном порядке. Вероятно, вы захотите изменить этот порядок.
#
LanguagePriority en da nl et fr de el it ja kr no pl pt pt-br ltz ca es sv tw
#
# ForceLanguagePriority позволяет вам (серверу) выдать конкретную страницу,
# вместо сообщения MULTIPLE CHOICES (задается Prefer), [в случае неоднозначного
# выбора], или сообщения NOT ACCEPTABLE (задается Fallback)[в случае, если
# не один язык не подошел]
#
ForceLanguagePriority Prefer Fallback
#
#
# AddDefaultCharset задает дефолтную таблицу символов (кодировку) для всех
# выдаваемых страниц. Это всегда полезно, и открывает возможность будущей
# мультилингвизации вашего веб сайта. Ее обозначение как дефолтной не
# наносит вреда, т.к. стандарт, в любом случае, определяет, что страница
# использует кодировку iso-8859-1 (latin1), если не указано иначе, т.е. вы
# просто подтверждаете очевидное. Существуют так же соображения о безопасности
# для браузеров, относящиеся к обработке javascript и URL, по которым всегда
# стоит указывать дефолтную кодировку.
#
AddDefaultCharset WINDOWS-1251
#
#
# Часто используемые расширения для обозначения кодировок. Вы, вероятно,
# захотите избежать столкновений с языковыми расширениями, если вы не
# специалист по тщательному тестированию установок после каждого изменения.
# См. «ftp://ftp.isi.edu/in-notes/iana/assignments/character-sets» для
# официального списка кодировок и соответствующих им документов RFC.
#
AddCharset ISO-8859-1 .iso8859-1 .latin1
AddCharset ISO-8859-2 .iso8859-2 .latin2 .cen
AddCharset ISO-8859-3 .iso8859-3 .latin3
AddCharset ISO-8859-4 .iso8859-4 .latin4
AddCharset ISO-8859-5 .iso8859-5 .latin5 .cyr .iso-ru
AddCharset ISO-8859-6 .iso8859-6 .latin6 .arb
AddCharset ISO-8859-7 .iso8859-7 .latin7 .grk
AddCharset ISO-8859-8 .iso8859-8 .latin8 .heb
AddCharset ISO-8859-9 .iso8859-9 .latin9 .trk
AddCharset ISO-2022-JP .iso2022-jp .jis
AddCharset ISO-2022-KR .iso2022-kr .kis
AddCharset ISO-2022-CN .iso2022-cn .cis
AddCharset Big5 .Big5 .big5
#
#
# Для русского языка используется более, чем одна кодировка (в основном,
# зависит от клиента):
#
AddCharset WINDOWS-1251 .cp-1251 .win-1251
AddCharset CP866 .cp866
AddCharset KOI8-r .koi8-r .koi8-ru
AddCharset KOI8-ru .koi8-uk .ua
AddCharset ISO-10646-UCS-2 .ucs2
AddCharset ISO-10646-UCS-4 .ucs4
AddCharset UTF-8 .utf8
#
#
# Ниже приведенный список не соответствует конкретному (iso) стандарту, но
# работает с довольно широким списком браузеров. Заметьте, что верхний регистр,
# на самом деле, имеет значение (этого не должно происходить, но с некоторыми
# браузерами, тем не менее, происходит).
#
# См. «ftp://ftp.isi.edu/in-notes/iana/assignments/character-sets» для своего
# рода списка (кодировок). Но браузеры поддерживают только некоторые из них.
#
AddCharset GB2312 .gb2312 .gb
AddCharset utf-7 .utf7
AddCharset utf-8 .utf8
AddCharset big5 .big5 .b5
AddCharset EUC-TW .euc-tw
AddCharset EUC-JP .euc-jp
AddCharset EUC-KR .euc-kr
AddCharset shift_jis .sjis
#
# AddType позволяет добавить новые MIME-типы (или переопределить старые из
# конфигурационного файла «mime.types») для определенных типов файлов.
#
AddType application/x-tar .tgz
#
# AddHandler позволяет связать определенные расширения имен файлов с
# обработчиками (handlers), вне зависимости от типа файла.
# Обработчики могут быть либо встроены в сервер, либо добавлены директивой
# Action (см. ниже).
#
# Для использования скриптов CGI вне директорий типа ScriptAliased :
# (Кроме того, вам придется добавить «ExecCGI» к директиве «Options»)
#
#AddHandler cgi-script .cgi
#
# Для файлов, которые включают свои HTTP заголовки:
#
#AddHandler send-as-is asis
#
# Для imagemap файлов, обрабатываемых сервером:
#
#AddHandler imap-file map
#
# Для type-maps (динамически определяемых ресурсов):
# Включено по умолчанию, чтобы допустить распространение страницы
# Apache «It Worked» («Сработало!») на различных языках.
#
AddHandler type-map var
#
#
# Фильтры позволяют обработать содержание до отправки клиенту.
#
# Для обработки .shtml файлов на предмет вставок, производимых сервером
# (server-side includes — SSI):
# (Кроме того, вам придется добавить «Includes» к директиве «Options»)
#
#AddOutputFilter INCLUDES .shtml
#
#
# Action позволяет определить MIME или другие типы (для которых задан
# какой-нибудь handler), при запросе которых выполняется соответствующий
# скрипт. Это устраняет необходимость многократного упоминания URL путей
# часто используемых скриптов CGI.
#
# Format: Action media/type /cgi-script/location
# Format: Action handler-name /cgi-script/location
#
# Формат: Action название_MIME_типа путь/скрипт
# Action назавние_типа_или_обработчика(handler) путь/скрипт
#
#
# Существует три типа настроек для конфигурируемых сообщений об ошибках:
# 1) простой текст 2) местные ссылки 3) внешние пересылки
#
# Некоторые примеры:
#
#ErrorDocument 500 «The server made a boo boo.»
#ErrorDocument 404 /missing.html
#ErrorDocument 404 «/cgi-bin/missing_handler.pl»
#ErrorDocument 402 http://www.example.com/subscription_info.html
#
# Собрав все это воедино, мы можем мультилингвизировать сообщения об ошибках.
#
# Мы используем Alias чтобы перенаправлять сообщения
# «/error/HTTP_<error>.html.var» на наборы сообщений на разных языках
# (собранных по типу ошибки). Мы используем «includes» для вставления
# необходимого текста.
#
# Alias /error/include/ «/your/include/path/»
#
#
# Можно изменить вид сообщения, не меняя никаких дефолтных
# «HTTP_<error>.html.var» файлов, добавив строку;
#
# Alias /error/include/ «/your/include/path/»
#
# которая позволяет вам создать свой набор файлов, начав с файлов
# «E:/Apache2/error/include/» и копируя их в «/your/include/path/»,
# в том числе и для отдельных VirtualHost.
#
#
<IfModule mod_negotiation.c>
<IfModule mod_include.c>
Alias /error/ "E:/Apache2/error/"
<Directory "E:/Apache2/error">
AllowOverride None
Options IncludesNoExec
AddOutputFilter Includes html
AddHandler type-map var
Order allow,deny
Allow from all
LanguagePriority en es de fr
ForceLanguagePriority Prefer Fallback
</Directory>
ErrorDocument 400 /error/HTTP_BAD_REQUEST.html.var
ErrorDocument 401 /error/HTTP_UNAUTHORIZED.html.var
ErrorDocument 403 /error/HTTP_FORBIDDEN.html.var
ErrorDocument 404 /error/HTTP_NOT_FOUND.html.var
ErrorDocument 405 /error/HTTP_METHOD_NOT_ALLOWED.html.var
ErrorDocument 408 /error/HTTP_REQUEST_TIME_OUT.html.var
ErrorDocument 410 /error/HTTP_GONE.html.var
ErrorDocument 411 /error/HTTP_LENGTH_REQUIRED.html.var
ErrorDocument 412 /error/HTTP_PRECONDITION_FAILED.html.var
ErrorDocument 413 /error/HTTP_REQUEST_ENTITY_TOO_LARGE.html.var
ErrorDocument 414 /error/HTTP_REQUEST_URI_TOO_LARGE.html.var
ErrorDocument 415 /error/HTTP_SERVICE_UNAVAILABLE.html.var
ErrorDocument 500 /error/HTTP_INTERNAL_SERVER_ERROR.html.var
ErrorDocument 501 /error/HTTP_NOT_IMPLEMENTED.html.var
ErrorDocument 502 /error/HTTP_BAD_GATEWAY.html.var
ErrorDocument 503 /error/HTTP_SERVICE_UNAVAILABLE.html.var
ErrorDocument 506 /error/HTTP_VARIANT_ALSO_VARIES.html.var
</IfModule>
</IfModule>
#
# Следующие директивы модифицируют обычное (в ответ на запросы HTTP)
# поведение сервера, с целью предотвращения некоторых известных проблем
# с конкретными браузерами.
#
BrowserMatch "Mozilla/2" nokeepalive
BrowserMatch "MSIE 4.0b2;" nokeepalive downgrade-1.0 force-response-1.0
BrowserMatch "RealPlayer 4.0" force-response-1.0
BrowserMatch "Java/1.0" force-response-1.0
BrowserMatch "JDK/1.0" force-response-1.0
#
#
# Следующая директива блокирует переадресацию по запросу
# (не использующую метод GET) для директории, не заканчивающейся
# на слэш. Это решает проблему с пакетом «Microsoft WebFolders»,
# который неправильно обрабатывает пересылки для папок методами
# DAV (коллективная система удаленного создания и контроля
# версий документов).
#
BrowserMatch "Microsoft Data Access Internet Publishing Provider" redirect-carefully
BrowserMatch "^WebDrive" redirect-carefully
#
# Разрешить выдачу сообщений-отчетов о состоянии сервера по запросу на URL
# «http://servername/server-status» . Замените «.admin.admin.com» на имя
# своего домена для включения.
#
#<Location /server-status>
# SetHandler server-status
# Order deny,allow
# Deny from all
# Allow from .admin.admin.com
#</Location>
#
#
# Разрешить выдачу сообщений-отчетов о конфигурации удаленного сервера по
# запросу на URL «http://servername/server-info» . Замените «.your-domain.com»
# на имя своего домена для включения.
#
#<Location /server-info>
# SetHandler server-info
# Order deny,allow
# Deny from all
# Allow from .admin.admin.com
#</Location>
#
# Директивы прокси-сервера. Раскомментируйте следующие строки, чтобы включить
# прокси-сервер.
#
#<IfModule mod_proxy.c>
#ProxyRequests On
#
#<Proxy *>
# Order deny,allow
# Deny from all
# Allow from .your-domain.com
#</Proxy>
#
#
# Включить/выключить обработку заголовков «HTTP/1.1» типа «Via:» (через)
# (Опция «Full» добавляет номер версии сервера, «Block» отменяет все исходящие
# заголовки типа «Via:».
# Возможные варианты: Off | On | Full | Block
#
#ProxyVia On
#
# Чтобы включить еще и кэширование, откорректируйте и раскомментируйте
# следующие строки
#
#CacheRoot «E:/Apache2/proxy»
#CacheSize 5
#CacheGcInterval 4
#CacheMaxExpire 24
#CacheLastModifiedFactor 0.1
#CacheDefaultExpire 1
#NoCache a-domain.com another-domain.edu joes.garage-sale.com
#</IfModule>
#
# Конец директив прокси сервера.
#
#
# Включить дополнительные конфиг-файлы для отдельных модулей
#
<IfModule mod_ssl.c>
Include conf/ssl.conf
</IfModule>
#
#
#
###Раздел 3: Виртуальные хосты
#
#
# VirtualHost: Если вы хотите держать множество доменов/хостов на своей машине,
# то задайте для них контейнеры VirtualHost. Большинство конфигураций задает
# только имена виртуальных хостов, с тем, чтобы серверу не требовались
# IP адреса. Данное обстоятельство обозначено звездочками (*) в следующих
# директивах.
#
# См. документацию по адресу <URL:http://httpd.apache.org/docs-2.0/vhosts/>
# для дополнительной информации, прежде чем создавать виртуальные хосты.
#
# Вы можете воспользоваться ключом «-S» для командной строки, чтобы выявить
# конфигурацию ваших виртуальных хостов.
#
#
#
# Использовать виртуальные хосты по их именам.
#
#NameVirtualHost *
#
#
# Пример виртуального хоста.
# Почти любые директивы Apache могут входить в контейнер VirtualHost.
# Первый VirtualHost используется для запросов, направленных на
# неизвестное имя сервера
#<VirtualHost *>
# ServerAdmin webmaster@dummy-host.example.com
# DocumentRoot /www/docs/dummy-host.example.com
# ServerName dummy-host.example.com
# ErrorLog logs/dummy-host.example.com-error_log
# CustomLog logs/dummy-host.example.com-access_log common
#</VirtualHost>
{kind=link}
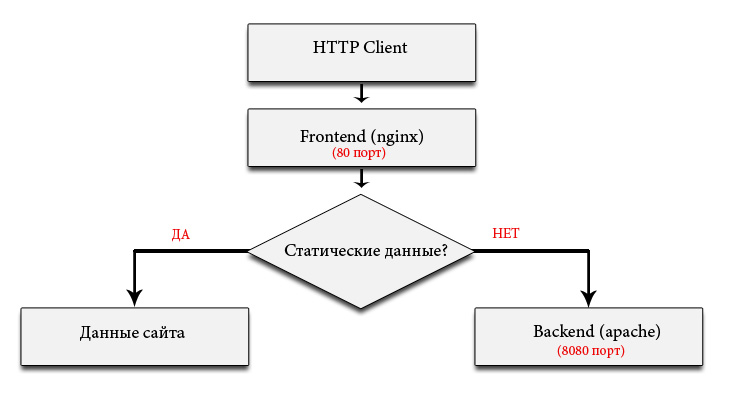

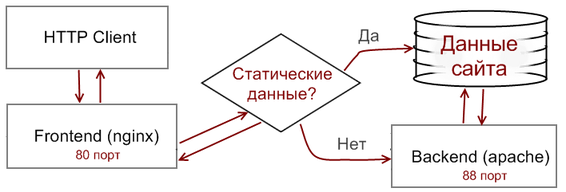 С помощью этих правил разруливаем запросы на отдачу статику и динамического контента
С помощью этих правил разруливаем запросы на отдачу статику и динамического контента